
How does Search Engine works?
How Does Search Engine work?
Before we go for How does Search Engine works let’s understand following nomenclature.
Spider
A search engine spider is a program that a search engine uses to seek out information on the web in an automated manner. Spider also is known as a bot, robot, or crawler. It follows links throughout the Internet, grabbing content from sites and adding it to search engine databases.
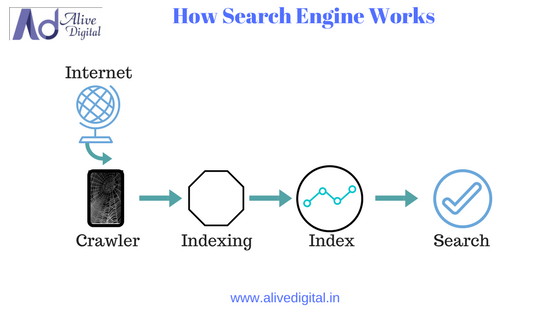
Crawling
Crawling is the process in which the crawler, bot, or spider which finds the documents on the World Wide Web. Web crawling is how the web spiders find documents on the web. The web spider typically starts crawling with the help of URL’s from the popular websites like Yahoo, MSN, etc, extracting the outgoing URL’S and crawls them. The spider crawls through the documents and run them through a spam and duplicates content filter placing then in the web index.
Indexing
Indexing is the process of recording information for easy and quick retrieval upon a search query. Indexing is the second major step a search engine takes to deliver information to your fingertips. A search engine must maintain a copy of all the content it finds during the crawl process, and
store it in an index for easy retrieval. Without an index, a search engine would have to re-run the crawl process for every search query performed. How exactly a search engine’s web index is designed and maintained is fairly complex and as an SEO it is beyond the need to know all the technical details.
As SEO’s we spend most of our time figuring out the Ranking part of the process, but the basics of indexing should be known and understood.
Cache Date
It’s the Date and time left by the spider when it has crawled the particular page of your website.
A search engine makes this index using a program called a ‘web crawler’. This automatically browses the web and stores information about the pages it visits.
Every time a web crawler visits a webpage, it makes a copy of it and adds its URL to an index. Once this is done, the web crawler follows all the links on the page, repeating the process of copying, indexing and then following the links. It keeps doing this, building up a huge index of many web pages as it goes. Some websites stop web crawlers from visiting them. These pages will be left out of the index, along with pages that no-one links to. The information that the web crawler puts together is then used by search engines. It becomes the search engine’s index. Every webpage recommended by a search engine has been visited by a web crawler.
To know more about How Search Engine Works and Digital Marketing join Alive Digital: Digital Marketing Training Institute in Pune or contact us.
You may also like

Explain What does “Keyword” in Digital Marketing.
